Providing customers with live data-driven flow rate predictions
The model is trained. It performs excellent on the test data. That means that we are finished with our work, right? Actually, the answer is no. Designing and training the model is just half the story.
- Author
- Kristoffer Nesland
- Publish date
- · 3 min read
The real value for the customer is not unleashed before they receive live flow rate predictions on how much oil, gas and water each of their wells produce. To accomplish this, we need to put our multi-task learning model into production.
Four steps are required to provide the customers with live flow rate predictions for a well. First, we stream temperature, pressure, valve opening and potentially other sensor data from the well. Then, we resample the sensor data to make sure that all of the time series are aligned and have values at the same points in time. Now, we are ready to feed the model with the data. Every time a set of new sensor data arrives from the well, the values are passed through the neural network together with information on which well the values originate from. After passing through all the hidden layers of the model, the input is transformed into three floating point numbers, one for each of oil, gas and water, all in standard cubic feet per day. Finally, the newly generated predictions are streamed back to the customer and find their way into various other use-cases, like allocation, production optimization and reservoir model update.
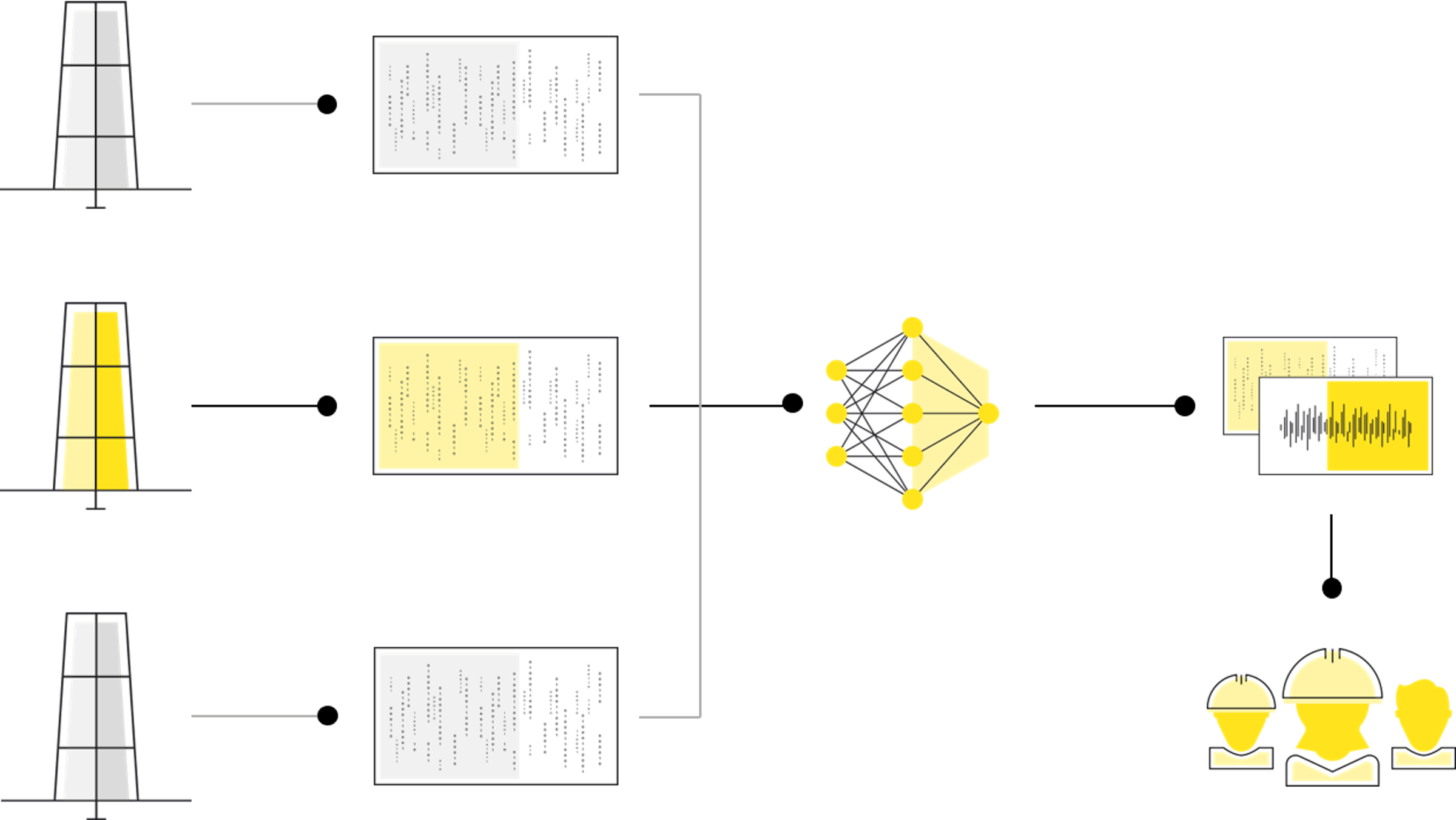
As seen in the previous posts about physicality and accuracy, the multi-task architecture provides benefits when it comes to prediction accuracy and robustness over time. Coincidentally, it turns out that the multi-task architecture also has some benefits when it comes to serving the rates live. To understand why, imagine that you would like to provide flow rate predictions for 50 individual wells. Without the multi-task architecture, you would need to train and keep track of 50 individual machine learning models. When time passes and new well tests are recorded you would need to re-train several models. Keeping all of these models up to data can become time consuming compared to a single model for all of the wells. A 50 well multi-task model will typically need significantly fewer parameters than 50 individual models combined. An added benefit here is reduced time needed for training the models. In the case of 50 wells, we have seen a reduced training time by a factor of around 4. All in all, improvements like this contribute to less time spent baby-sitting the models and higher uptime.
In Solution Seeker, we have a strong focus on productifying our research. The work on multi-task learning for flow rate estimation presented here is a prime example of this. As seen, the approach leads to solid research results and at the same time it simplifies the process of providing our customers with flow rate estimations. Solutions like this prove that high performance does not always need to come at the expense of additional complexity.
If you would like a demo or discuss data-driven flow rate solutions for your asset, don’t hesitate to get in touch.