Learning mechanistic features across wells and assets
Even models with great test performance may suffer from lack of interpretability. If the explanatory variables depend on one another, it is difficult to isolate the effect of any individual variable. Can multi-task learning be the solution?
- Author
- Kristoffer Nesland
- Publish date
- · 3 min read
One example is the observation that choke openings are continuously adjusted to counteract the declining reservoir pressure as described in a previous post. Models trained on data from a single well are vulnerable to such correlated explanatory variables and how data change with time. Training on data from multiple wells is one attempt to overcome these issues. We wanted to investigate whether learning across wells gave multi-task models properties more similar to those we would expect from a mechanistic interpretation than single-task models. By visualizing model predictions and creating a simple metric, we explored whether data sharing across assets made the models correspond to mechanistic expectations to a higher degree.
As described in the last post, we conducted a broad case study of 55 wells from four oil and gas assets and steady-state production data spanning several years. As part of the study we wanted to explore the robustness of different data-driven models on unseen data samples. Would the model predictions correspond to the mechanistic expectation that an increase in the upstream pressure should lead to increased flow rates?
To explore further, we selected a subset of 30 data points from the test sample for each well. For each of the 30 data points, we evaluated the corresponding single-task neural network model and the multi-task model trained on all assets in a neighborhood around the observed value by varying the upstream pressure.
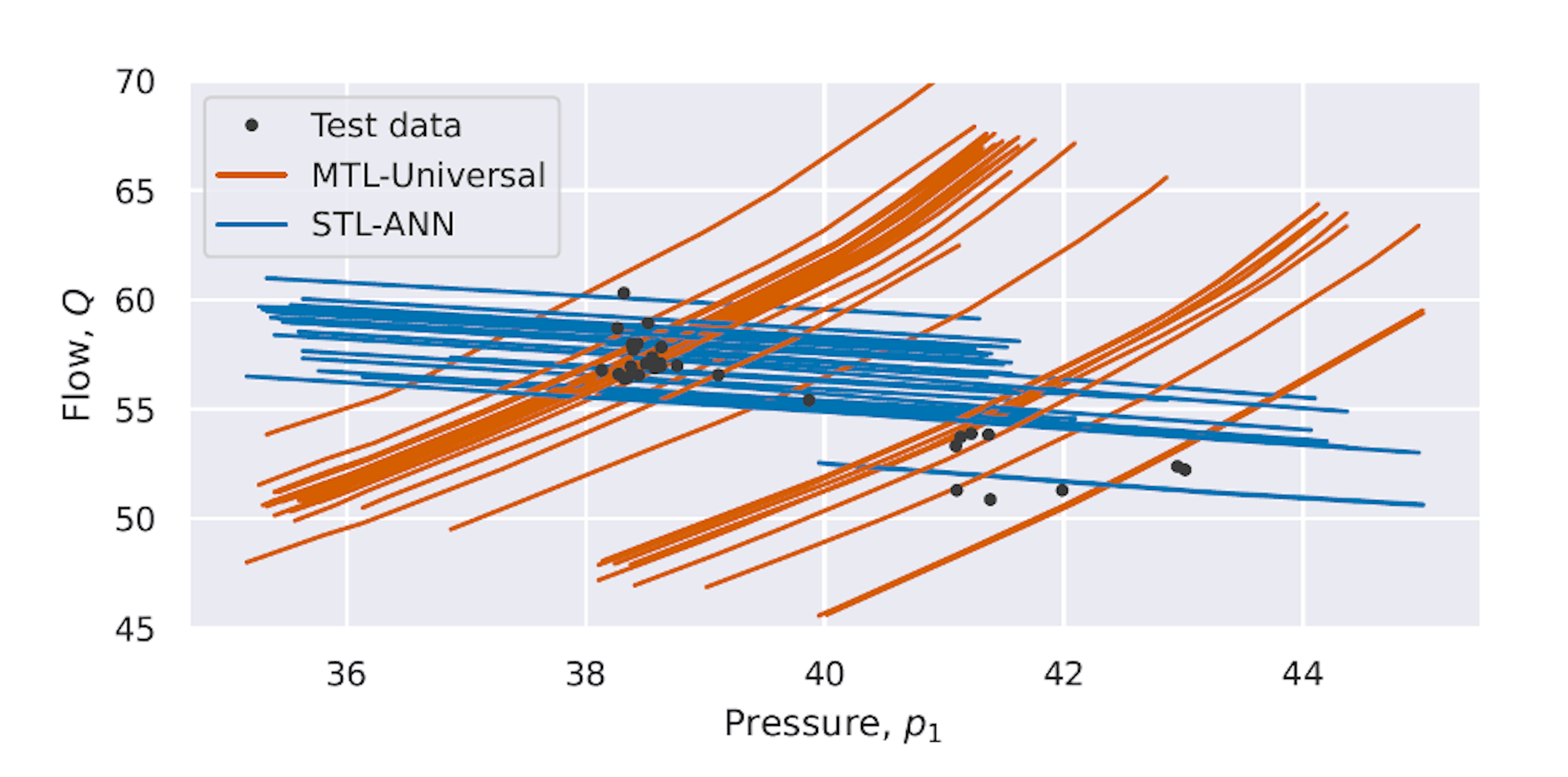
The results for one of the wells is shown in the figure. Both the corresponding single-task neural network model (STL-ANN, shown in blue) and the multi-task model trained on all assets (MTL-universal, shown in orange) had low test errors, with trimmed mean absolute percentage error of 2.2% and 1.6% respectively. Even so, the figure shows that there is a significant difference in how the models interpret upstream pressure as an explanatory variable. In this case, the multi-task learning model was able to identify the expected response, while the single-task model was not.
To generalize the comparison across wells and model types, we decided to create a simple metric of whether the sensitivity of the model corresponded to the mechanistic expectation. For each well data point and model, we compared the estimate from the model and the estimate from the model when all variables are kept constant except for an increase in the upstream pressure by 10 bar. For each model type we computed the fraction of predictions where an increase in upstream pressure led to a decrease in the flow rate estimate. The ratio of “bad” predictions, predictions that do not correspond to the mechanistic expectation, may then be compared between model types. Zero is the best score, indicating that all predictions behaved as expected. MTL-universal, with a score of 0.07, ended up beating the STL-ANN score of 0.28.
Most of the wells remain unchanged or achieve a better sensitivity score by sharing data with other wells. This is one clear advantage of the multi-task learning approach
Transferring knowledge among wells and assets seems valuable. Perhaps a hybrid modeling approach utilizing knowledge across assets and complementing with mechanistic insights would yield even better results?
Our next post will focus on how the multi-task learning approach affects value creation and simplifies model maintenance.
- Multi-task learning for virtual flow metering
-
Sandnes, A.T., Grimstad, B., Kolbjørnsen, O., 2021
Link