Calibration plots - how confident is your model about itself?
Calibration plots can be used to analyze probabilistic models. In short, the plot casts light upon how confident or uncertain a model is about its own predictions, and if we, as users of the model, can trust this uncertainty. Let us explain how.
- Author
- Solution Seeker
- Publish date
- · 4 min read
Imagine that you have a model that predicts the flow rate of oil from a petroleum well given its surrounding conditions. It is crucial that you know how much oil will be produced when adjusting the control valve opening. Why? There are numerous restrictions on how much oil you can produce, both economically and politically. Further, producing too much from the well may damage the structure in the reservoir for instance by inducing water breakthrough or excessive sand production.
90%
Alright, so you adjust your valve opening to 50% and you demand of your model to know how much oil will be produced. And the model gives you a number, say 800bbl/d. But how certain is this number? If the well actually produces 900bbl/d for this valve opening you might eventually face a problem with OPEC as you produce more than you planned for. If the well produced 700bbl/d you will definitely lose economically. Wouldn't it be marvelous if you knew how certain your model was about that number? Now, a probabilistic model will at least give you an estimate of the uncertainty. You will not only get the value 800bbl/d, but your model will tell you that there might be a 90% chance that you will produce 900bbl/d. Will you risk this? Maybe not. What if the model said that there is only 5% chance that you will produce 900bbl/d? A lot better risk to take, no? But then again, how certain is this uncertainty? Can we trust the model uncertainty? The answer is, you need to analyze the model with a calibration plot.
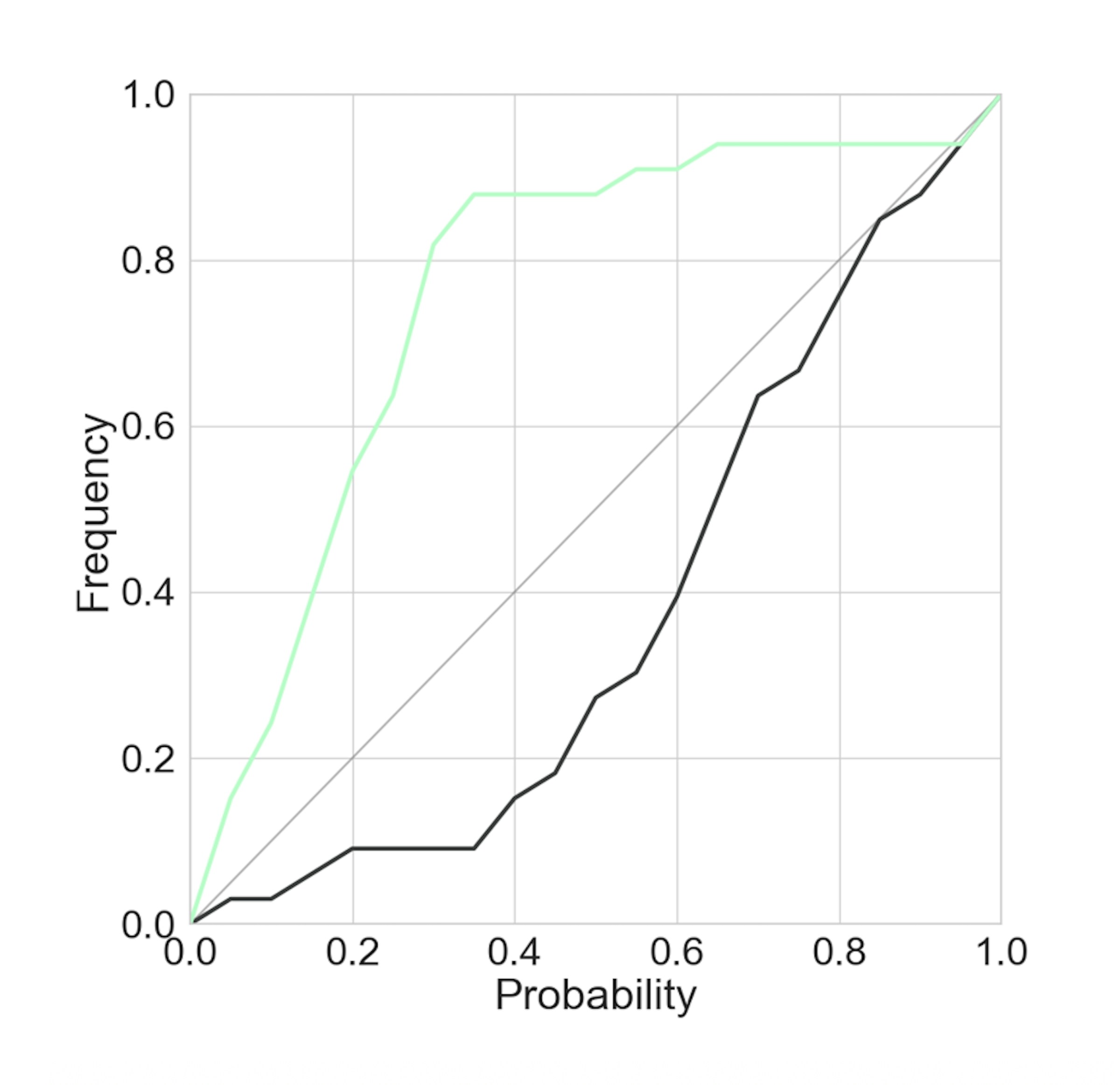
Let us jump straight into the calibration plot by looking at some figures. In Figure 1, two calibration plots of two different models (green and black) are illustrated. The models are evaluated on a test data set. The graphs show the frequency of residuals lying within varying posterior intervals of the predictive distribution. Another word for these intervals are credible intervals. A perfectly calibrated model should lie along the diagonal, gray line. Wait, what? Frequency of residuals, what does that even mean? Let's take it step-by-step.
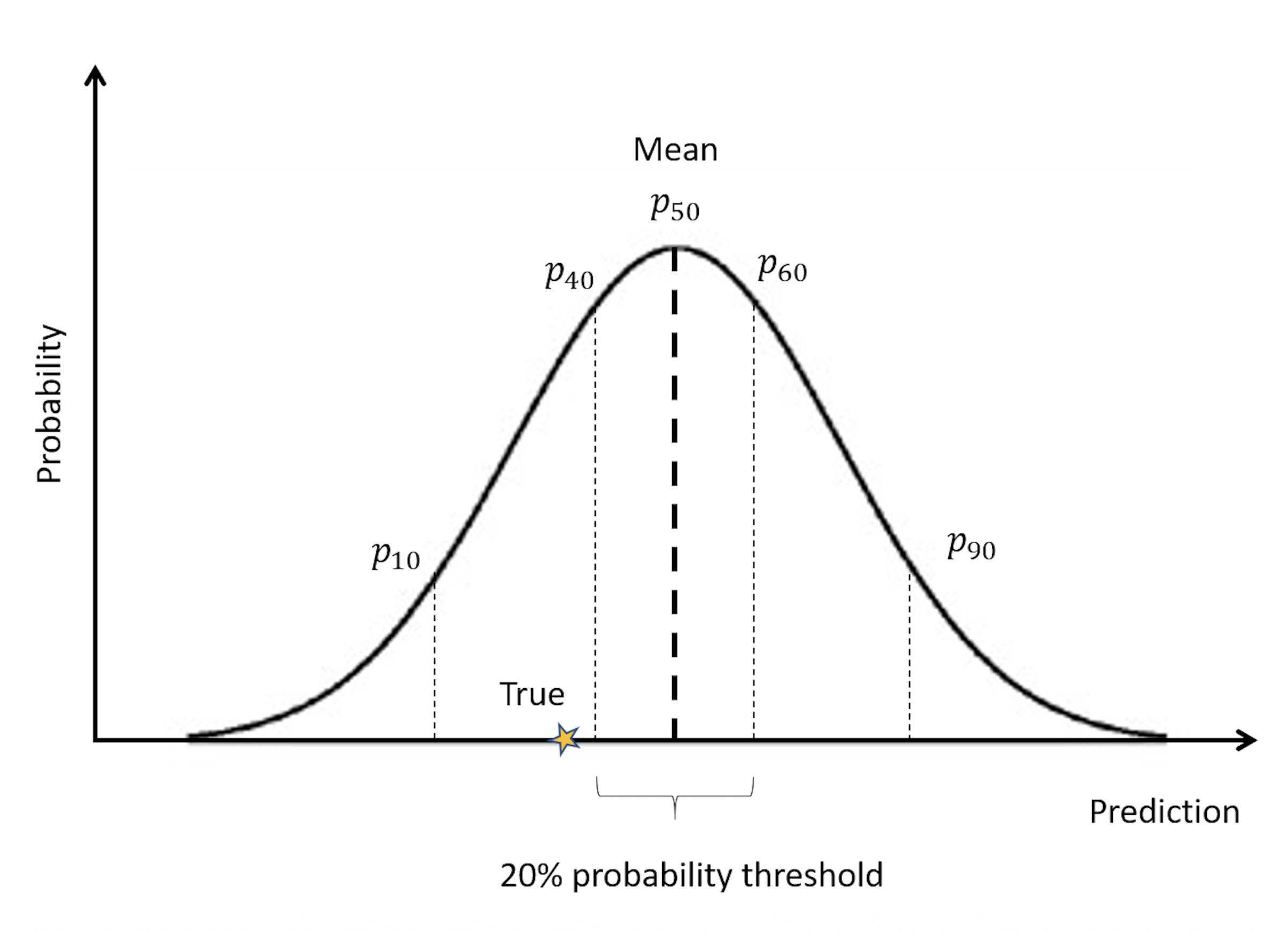
First, imagine a new measurement point for which you use your model to predict the output. Now, as your model is probabilistic, it will not only give out a point estimate but a distribution. For instance, if your model follows a normal distribution, the predictive distribution will look like the bell-shaped one illustrated in Figure 2. The black dotted line in the middle is your model's median predictive value (for the normal distribution the median corresponds to the mean) for the measurement point, also called the 50th (P50) percentile. A percentile is basically just an expectation of the percentage of the data points that will have a value lower than the value at the percentile. For instance, if the 40th percentile has a value of 5, it is expected that 40% of all data points will have a value lower than 5. We have also indicated the 20% posterior interval centered about the median, which is the area in between the percentiles P40 and P60. This means that we expect 20% of data points to fall within this threshold.
Alright, we have our model posterior predictive distribution for the new measurement point, let us now indicate where the true measurement value actually lies in relation to this distribution. This is indicated by the yellow star. From this we can determine which posterior interval the true value lies in. If we do this exercise for all the test points in our test data set, we can calculate the frequency of residuals lying within varying posterior intervals centered around the median. A perfectly calibrated model will have 20% of the test points lying in the 20% probability threshold and so forth. In other words, on the gray diagonal line in the calibration plot in Figure 1. If so, this means that we can trust the uncertainty in the predictions that the model believes it has.
Let's get back to the illustrated calibration plots in Figure 1. From the figures we see that none of the models are well calibrated. The model with its curve above the diagonal (green) shows an under-confident model. This is because there is a greater percentage of test points that lies within a certain threshold than the model was expecting. For instance, more than 50% of the test points lie within the 20% probability threshold. Ergo, the model lacks confidence in its own predictions. The model with its curve below the diagonal (black) shows an overconfident model. Here only about 10% of all test points lie within the 20% probability threshold. The model is therefore too cocky about its own predictions.
Stay tuned for our next article in this series, where we will explore the uncertainty of the results from our large-scale study of data-driven VFMs using Bayesian neural networks. Read our previous articles on data-driven VFMs here.